
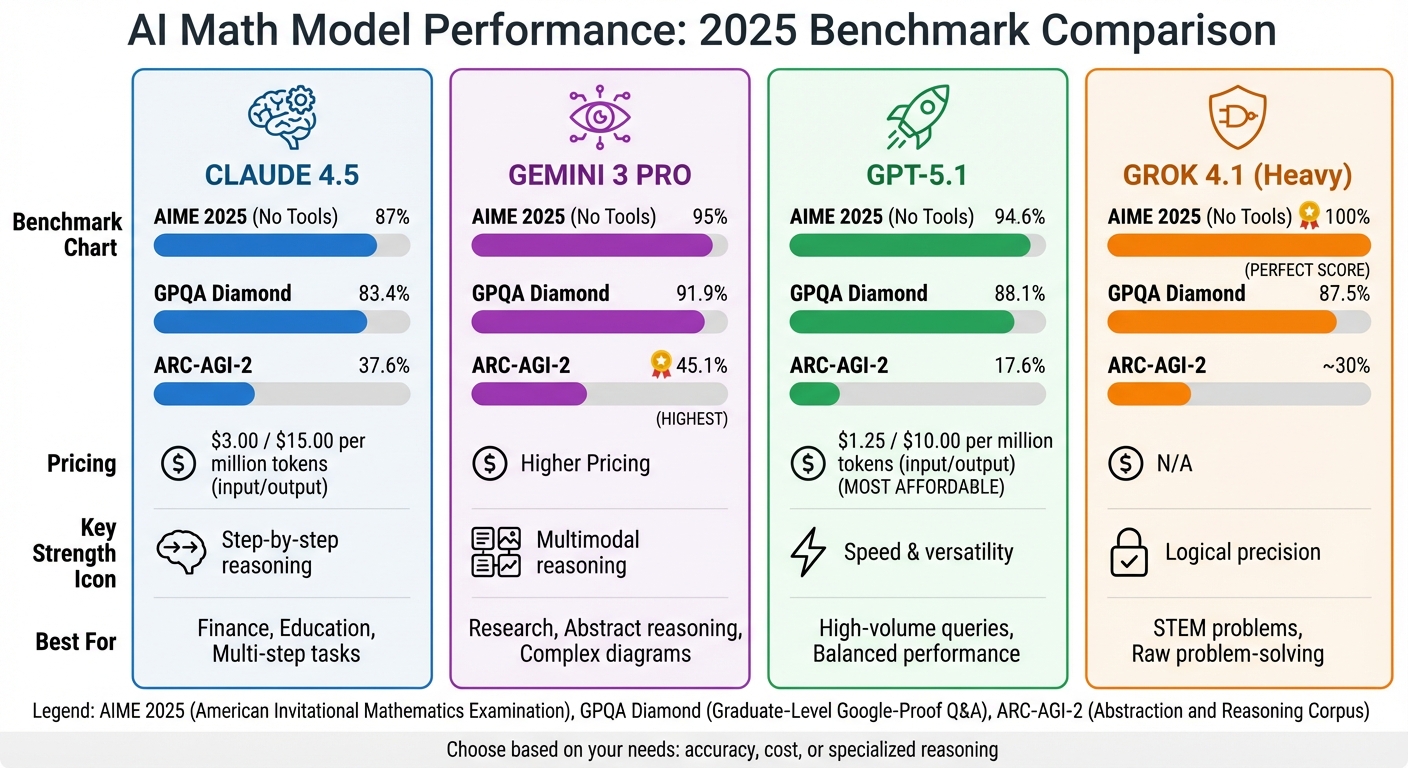
Which AI model is best at math? It depends on what you’re looking for. Here’s a quick breakdown of how the top models performed on math benchmarks in 2025:
- Claude 4.5: Great for consistent, step-by-step reasoning and tool use. Scored 87% on AIME 2025 without tools, and 83.4% on GPQA Diamond. It’s reliable for tasks like coding, finance, and education. Pricing: $3.00 per million input tokens, $15.00 per million output tokens.
- Gemini 3 PRO: Excels at multimodal reasoning (e.g., charts, diagrams). Scored 95% on AIME 2025 without tools and leads on abstract reasoning benchmarks like ARC-AGI-2 (45.1%). It’s ideal for research-heavy tasks. Pricing is higher, but it delivers top-tier performance.
- GPT-5.1: Balances speed and accuracy. Scored 94.6% on AIME 2025 without tools and 88.1% on GPQA Diamond. Affordable at $1.25 per million input tokens, $10.00 per million output tokens.
- Grok 4.1: Focused on logical precision. Scored 100% on AIME 2025 with tools but struggles with abstract reasoning. Best suited for raw problem-solving in STEM fields.
Quick Comparison
| Model | AIME 2025 (No Tools) | GPQA Diamond | ARC-AGI-2 | Pricing (Input/Output) |
|---|---|---|---|---|
| Claude 4.5 | 87% | 83.4% | 37.6% | $3.00 / $15.00 |
| Gemini 3 PRO | 95% | 91.9% | 45.1% | Higher Pricing |
| GPT-5.1 | 94.6% | 88.1% | 17.6% | $1.25 / $10.00 |
| Grok 4.1 (Heavy) | 100% | 87.5% | ~30% | N/A |
Each model has strengths: Claude 4.5 is dependable for multi-step tasks, Gemini 3 PRO excels in research, GPT-5.1 is affordable and versatile, and Grok 4.1 is precise for STEM problems. Choose based on your needs and budget.
AI Model Math Benchmark Comparison: Claude 4.5 vs Gemini 3 PRO vs GPT-5.1 vs Grok 4.1
Claude 4.5: Math Benchmark Performance
Benchmark Results and Strengths
Claude Sonnet 4.5 hit a perfect 100% on the AIME 2025 benchmark when using Python tools, securing its spot among the top mathematical reasoning models. Even without tools, it scored an impressive 87%, showcasing its strong logical capabilities. These results highlight its potential for tackling advanced benchmarks.
On the GPQA Diamond benchmark, designed to test PhD-level scientific and mathematical knowledge, Claude Sonnet 4.5 earned an 83.4% score. While this is slightly behind competitors like Gemini 3 PRO (91.9%) and GPT-5.2 (92.4%), it still demonstrates graduate-level proficiency in handling complex problems.
The model’s strengths lie in its multi-step reasoning, consistent accuracy during extended tasks, and its ability to integrate tools like Python to avoid errors. It excels at breaking problems into smaller, solvable steps and delegating precise arithmetic calculations to Python. On Dutch high school math exams, the model achieved 94% accuracy, tying for first place. Maarten Sukel, an AI researcher, commented:
"Claude Sonnet 4.5 delivers Mistral-level speed (4.9 seconds) with 94% mathematics accuracy – the highest score in my entire benchmark."
The model also reduced code editing errors from 9% to 0% and cut "shortcut" behavior – where models abandon tough problems – by 65%. These improvements make it a powerful tool across industries like finance, education, and research.
Practical Applications
Claude 4.5’s advanced math skills translate directly into practical, real-world scenarios. In finance, it excels at tasks like risk assessment, structured product analysis, and portfolio screening. Anthropic notes:
"For complex financial analysis – risk, structured products, portfolio screening – Claude Sonnet 4.5 with thinking delivers investment-grade insights that require less human review."
In education, the model acts as a patient tutor for STEM subjects, guiding students through calculus, physics, and engineering problems step by step. It annotates diagrams, points out relevant theorems, and identifies hidden assumptions in proofs.
For research, Claude 4.5 assists scientists and engineers by deriving formulas, analyzing experimental data, and integrating with technical tools. Whether it’s calculating wing loading for aerospace design or processing entire litigation briefings for legal analysis, the model’s ability to maintain focus over extended sessions makes it a valuable partner in projects requiring deep, sustained analysis.
ChatGPT/Gemini 3/Grok: Which is Better for Research Maths?

Competitor Analysis: Gemini 3 PRO, GPT-5.1, and Grok 4.1
Now that we’ve reviewed Claude 4.5’s benchmark performance, let’s take a closer look at how its competitors measure up.
Gemini 3 PRO: Multimodal Math Powerhouse
Gemini 3 PRO stands out for its exceptional mathematical reasoning, achieving a stellar score of 91.9% on GPQA Diamond. On the AIME 2025 benchmark, it reached 95.0% without tools, outperforming both Claude 4.5 and GPT-5.1. What sets Gemini 3 PRO apart is its ability to process text, images, audio, and video through a unified system. This capability shines when tackling tasks involving complex charts, technical diagrams, and mathematical text all at once.
One of its standout features, "Deep Think" mode, dedicates extra computational resources to enhance abstract reasoning. This mode helped Gemini 3 PRO score 45.1% on ARC-AGI-2, far surpassing GPT-5.1’s 17.6% and even outperforming Claude 4.5’s 37.6%. Its 1-million-token context window enables it to analyze entire technical books or massive datasets in a single go. Gemini 3 PRO also became the first model to break the 1500 Elo barrier on LMArena, achieving a score of 1501.
GPT-5.1: Quick and Versatile Reasoning
GPT-5.1 takes a different approach, focusing on speed and dual-mode reasoning. Its system toggles between "Instant" and "Thinking" modes, adjusting reasoning depth based on task complexity. On AIME 2025, it scored 94.6% without tools, trailing Gemini 3 PRO but beating Claude 4.5’s 92.8%. It also performed well on MMMU, a benchmark for multimodal understanding, with a score of 84.2%. However, its tendency to overlook earlier constraints can be a drawback in complex tasks.
On GPQA Diamond, GPT-5.1 achieved 88.1%. At a cost of $1.25 per 1 million input tokens and $10.00 per 1 million output tokens, GPT-5.1 offers a balance of affordability and versatility, making it a strong all-around option.
Grok 4.1: Logical and Algorithmic Precision
Grok 4.1 excels in rigorous, low-level calculations, often favoring brute-force methods over streamlined solutions. Its Grok 4 Heavy variant achieved a perfect 100% on AIME 2025, outperforming both Claude 4.5’s 92.8% and Gemini 3 PRO. On GPQA Diamond, Grok 4 Heavy scored 87.5%, placing it ahead of Claude 4.5 but behind Gemini 3 PRO.
Professional mathematicians have praised Grok 4.1 for its capabilities in mathematical literature searches and source comparisons. Bartosz Naskręcki remarked:
"Grok 4 excels at web searches and source comparison… it might become my go-to model for first search in the field."
However, Grok 4.1 has its limitations. It struggles with spatial reasoning and lacks the mathematical creativity needed to identify conceptual shortcuts. Its proof-writing can be inconsistent, sometimes leaving logical gaps or offering overly brief justifications compared to Claude’s detailed approach. That said, its 2-million-token context window and focus on computational rigor make it a strong choice for STEM tasks that demand raw problem-solving power.
These models demonstrate distinct strengths, each tailored to specific needs in STEM applications, from abstract reasoning to brute-force calculations.
sbb-itb-f73ecc6
Head-to-Head Benchmark Comparison
Benchmark Comparison Table
When comparing performance across demanding math benchmarks, the differences between Claude 4.5, Gemini 3 PRO, GPT-5.1, and Grok 4.1 become clear:
| Benchmark | Gemini 3 PRO | GPT-5.1 | Claude 4.5 | Grok 4.1 (Heavy) |
|---|---|---|---|---|
| AIME 2025 (No Tools) | 95.0% | 94.0% | 87.0% | 100% |
| GPQA Diamond | 91.9% | 88.1% | 83.4% | 87.0% |
| MathArena Apex | 23.4% | 1.0% | 1.6% | N/A |
| MATH Level 5 | N/A | 98.1% | 97.7% | N/A |
| Humanity’s Last Exam | 37.5% | 26.5% | 13.7% | ~30% |
Grok 4.1 (Heavy) earns a perfect score on AIME 2025, while Gemini 3 PRO dominates MathArena Apex and Humanity’s Last Exam. GPT-5.1 stands out on MATH Level 5 with near-perfect accuracy. Although Claude 4.5 lags slightly in raw math performance, it still delivers consistent results in the 80–90% range on several benchmarks.
These numbers provide a foundation for understanding the distinctive strengths and strategies of each model.
Performance Trends and Analysis
Digging deeper into the results, we see how each model approaches problem-solving differently. Gemini 3 PRO’s "Deep Think" mode is a standout feature, channeling additional computational resources into tackling complex problems. This approach explains its impressive 23.4% score on MathArena Apex, a benchmark where Claude 4.5 and GPT-5.1 barely reach 2%. While this mode prioritizes accuracy over speed, it makes Gemini an excellent choice for research-heavy fields like advanced mathematics or theoretical physics.
On the other hand, GPT-5.1 excels in scenarios involving code execution. It achieves perfect scores on AIME 2025 when it can verify calculations using Python but sees a sharp drop to 71% when relying solely on internal reasoning. This highlights the model’s reliance on external tools to maintain accuracy, which could be a limitation in environments where such tools aren’t available.
Reliability also sets these models apart. GPT-5.1’s dual-mode system (Instant vs. Thinking) offers flexibility but has been noted to sometimes miss constraints in multi-step problems. Claude 4.5, while slower, is praised for its consistent, step-by-step reasoning that rarely veers off course. This makes it a strong contender for high-stakes calculations where even minor errors can have significant consequences.
Finally, pricing plays a crucial role in choosing the right model. For users processing large volumes of math problems daily, GPT-5.1’s lower cost is an advantage. However, for those tackling complex, cutting-edge research questions, Gemini’s superior reasoning capabilities may justify its higher price tag.
Conclusion: Which Model Performs Best in Math?
After diving into the benchmark analysis, it’s clear that no single model dominates across all areas. Each one shines in its own way. GPT-5.2 takes the crown for mathematical reasoning, scoring a perfect 100% on AIME 2025 without relying on external tools.
Gemini 3 PRO stands out in research-level math and abstract reasoning, scoring 37.6% on FrontierMath and 37.5% on Humanity’s Last Exam. Its "Deep Think" mode is particularly effective when tackling complex diagrams, charts, or multimodal problems – tasks where other models often fall short.
Claude 4.5, on the other hand, excels in practical, real-world applications requiring long-term focus and seamless tool use. While its benchmark scores may not top the charts, it’s highly reliable for extended tasks. For instance, it scored 77.2% on SWE-bench Verified, showcasing its ability to handle intricate coding challenges. Whether it’s financial analysis, multi-file engineering projects, or tasks demanding sustained accuracy, Claude 4.5 proves to be a dependable choice.
Key Takeaways
The pricing of each model aligns with its strengths. GPT-5.1 offers the most budget-friendly option, making it perfect for handling high volumes of standard queries. Claude 4.5 delivers great value for complex reasoning tasks, offering intelligence-per-token efficiency. Meanwhile, Gemini 3 PRO justifies its higher cost with unmatched capabilities in research-level mathematics.
FAQs
How does Claude 4.5 perform in math compared to other AI models?
Claude 4.5 (Opus 4.5 variant) demonstrates impressive math capabilities, ranking just below Google’s Gemini 3 Pro and matching OpenAI’s GPT-5.1 in reasoning and quantitative benchmarks. It scored 70 on the Artificial Analysis Intelligence Index, placing it among the top-performing models in these areas.
Although Gemini 3 Pro holds the highest score overall, Claude 4.5 surpasses Grok 4.1, which is more focused on affordability than advanced reasoning skills. This positions Claude 4.5 as a strong contender for tasks requiring math proficiency and logical reasoning.
What can Claude 4.5’s math skills be used for in real-world scenarios?
Claude 4.5 brings impressive math skills to the table, making it a powerful tool for a variety of tasks. It can handle everything from automating spreadsheet calculations and tackling financial or scientific models to solving intricate quantitative problems. These abilities also integrate seamlessly into code-based workflows, paving the way for creating AI agents tailored to specific needs.
Thanks to its sharp reasoning capabilities, Claude 4.5 shines in areas that demand accuracy and efficiency. Whether it’s fine-tuning budgets, spotting data trends, or simplifying complex technical processes, it delivers reliable and effective results.
What makes Claude 4.5 a strong choice for math-related tasks compared to other AI models?
Claude 4.5 shines for its strong reasoning and math skills, consistently leading the pack in math-related benchmarks. It earned the top spot on the Artificial Analysis Intelligence Index, showcasing its ability to tackle complex problems with precision and dependability.
Built with enhanced reasoning and accuracy, Claude 4.5 is ready to take on a variety of math challenges, making it an ideal pick for users seeking smart and reliable solutions.