
Anthropic‘s latest AI model lineup, Claude 4.5, introduces three models: Opus 4.5, Sonnet 4.5, and Haiku 4.5. Each is designed for specific tasks, such as reasoning, coding, and autonomous workflows. Here’s what you need to know:
- Claude Sonnet 4.5: Best for advanced coding tasks, available since September 29, 2025.
- Claude Opus 4.5: The most capable model for high-stakes workflows, released November 24, 2025.
- Claude Haiku 4.5: A cost-effective option offering 90% of Sonnet’s performance.
Key Updates:
- Improved Efficiency: Tasks that took 2 hours now take 30 minutes with Opus 4.5.
- New Features: Context compaction for better memory management and agent tools for long-term autonomy.
- Security Upgrades: Better defenses against prompt injection and adversarial attacks.
- Developer Tools: Enhanced SDKs for building agents and automating workflows.
Pricing:
- Sonnet 4.5: $3 per million input tokens, $15 per million output tokens.
- Opus 4.5: Premium pricing for demanding tasks.
These updates make Claude 4.5 a powerful tool for U.S. developers and businesses, especially in coding, research, and secure enterprise applications.
Introducing Claude Opus 4.5
Technical Updates and New Features
Claude 4.5 brings improved reasoning capabilities, enhanced reliability, and better token efficiency compared to earlier 4.x models. These updates streamline multi-step coding and agent tasks, cutting down unnecessary steps and backtracking. Benchmark tests reveal a 15% performance boost on Terminal Bench and a significant reduction in task completion time – from 2 hours to just 30 minutes. These advancements lay the groundwork for the specific improvements detailed below.
Reasoning and Speed Improvements
Both Opus 4.5 and Sonnet 4.5 excel in handling complex, multi-step reasoning and enterprise-level tasks, including long-horizon coding. Opus 4.5, in particular, uses fewer tokens than earlier versions, which helps lower overall API costs. This model maintains coherent reasoning across extended coding sessions and large codebases, offering more accurate planning, better refactoring, and dependable multi-step execution. Developers can also adjust the balance between response depth, latency, and cost using the effort control features available on the Claude Developer Platform.
Context Window Updates
Claude 4.5 introduces context compaction, a feature that automatically summarizes and compresses earlier parts of a conversation or task. Instead of simply cutting off older messages, the platform extracts and retains key decisions and constraints while discarding unnecessary details. This process works hand-in-hand with new agent memory tools and context editing options in the Claude API, enabling longer and more complex sessions without running into context limits. When paired with Opus 4.5, these upgrades have increased deep research evaluation scores by approximately 15 percentage points.
Security Updates
Claude 4.5 is Anthropic’s most safety-focused model to date, designed to minimize risks such as sycophancy, deception, and power-seeking behaviors seen in earlier versions. Opus 4.5 stands out for being significantly harder to manipulate through prompt injection compared to other leading models, as confirmed by Anthropic’s internal safety tests and red-teaming evaluations. The model has undergone extensive training to ensure safer interactions when using tools, browsing, or controlling systems. These improvements make Claude 4.5 a more dependable choice for organizations looking to guard against jailbreaks and data breaches via prompt-based attacks.
Developer Tools and Resources
Alongside the technical and security updates, Anthropic has introduced a suite of developer tools designed to maximize the capabilities of Claude 4.5. A notable addition is the Claude Agent SDK, which provides access to the core infrastructure of Claude Code. This SDK offers essential features like tool integration, multi-step task planning and execution, and context management. Below, we’ll break down the key updates and resources available to developers.
Claude Agent SDK
The Claude Agent SDK is a game-changer for developers aiming to tackle complex tasks efficiently. It allows developers to plan workflows, execute tools, and refine processes until the desired outcomes are achieved – all with minimal manual input. For instance, an agent can handle tasks like automating repository refactoring by running git commands, performing tests, and adjusting code based on results. U.S.-based startups and enterprises are already leveraging these agents for tasks such as creating coding copilots, generating automated reports, building KPI dashboards, and routing documents. Some of these processes can run for extended periods – up to 30 minutes or more – with little to no human involvement.
The SDK also provides flexibility and control. Developers can restrict agent permissions (e.g., setting tools to read-only or write access), configure effort control to manage costs versus reasoning complexity, and add human-in-the-loop checkpoints for critical actions like database updates or credential handling.
API and Application Updates
The Claude API introduces new model identifiers: claude-sonnet-4-5 and claude-opus-4-5. Sonnet 4.5 serves as a direct replacement for Sonnet 4, maintaining the same pricing while offering better performance in coding and reasoning tasks.
Claude Code now includes an upgraded Plan Mode, which generates a structured plan.md file after asking clarifying questions. This feature ensures developers can review or adjust plans before execution, minimizing errors during complex operations like multi-file refactoring. Additionally, the platform now supports code execution and file creation directly within conversations. This means developers can work on spreadsheets, slides, and documents without needing to switch between tools, streamlining workflows for intricate tasks.
Another exciting update is the beta release of Claude for Excel, which brings AI-powered assistance into Excel. This feature simplifies the creation of pivot tables, charts, and data summaries, all formatted in familiar U.S. standards like USD currency and MM/DD/YYYY dates.
Pricing and Access
When it comes to pricing, Claude Sonnet 4.5 is available at $3 per million input tokens and $15 per million output tokens – the same as Sonnet 4 but with enhanced performance. Meanwhile, Claude Opus 4.5 is positioned at a higher price point than Sonnet but remains more affordable than earlier Opus models. It’s tailored for high-value tasks where deeper reasoning is essential.
Organizations in the U.S. often use Sonnet 4.5 for everyday needs like chatbots, internal tools, and standard coding assistance. Opus 4.5, on the other hand, is reserved for more demanding applications, including critical agents, advanced research, and high-stakes decision-making. Claude Pro subscribers gain access to Opus 4.5 as part of their plan, while enterprise clients can negotiate terms for large-scale deployments, including capacity and data-governance guarantees.
These updates not only enhance developer tools but also align them seamlessly with Claude 4.5’s advanced capabilities, making it easier to tackle even the most complex projects.
sbb-itb-f73ecc6
Performance Metrics and Comparisons
Claude Opus 4.5 vs Sonnet 4.5: Performance and Pricing Comparison
Claude 4.5 marks a notable step forward in both its capabilities and efficiency. Anthropic has shifted its focus from traditional single-prompt benchmarks to more complex multi-step tasks, tool usage, and long-term workflows. Both Opus 4.5 and Sonnet 4.5 show clear improvements over earlier Claude versions and competitors, particularly in reasoning, coding, and autonomous workflows.
Benchmark Results
On Terminal Bench – a test designed to evaluate terminal and tool-use coordination – Opus 4.5 outperforms Sonnet 4.5 by 15%, showcasing better planning and efficiency. Anthropic’s internal evaluations, which assess context management, memory, and advanced tool usage, further highlight Opus 4.5’s strengths. For long-duration coding tasks (spanning 30 minutes or more), both models maintain consistent performance across large codebases, a significant leap in reliability compared to earlier versions. Businesses report that tasks previously taking about two hours can now be completed in just 30 minutes using Opus 4.5-powered agents – a fourfold reduction in time – while improved token efficiency leads to cost savings for U.S. companies.
These performance gains set the stage for the safety and accuracy advancements discussed below.
Safety and Accuracy Improvements
Anthropic describes Sonnet 4.5 as "the most aligned frontier model we’ve ever released", highlighting reductions in sycophancy, deception, power-seeking behaviors, and delusional responses compared to earlier Claude versions [2, 12]. Both models demonstrate significant progress in resisting prompt injection attacks, with Anthropic noting that Opus 4.5 is the most resilient frontier model to date. These advancements are especially critical for high-risk environments like finance, cybersecurity, and legal workflows, where adversarial attacks and instruction errors can have serious consequences. Enhanced factual accuracy and better adherence to instructions make these models more dependable for tasks such as analyzing litigation documents, drafting business reports with U.S.-specific formatting (MM/DD/YYYY dates, USD currency), and navigating American regulatory materials [2, 4, 5].
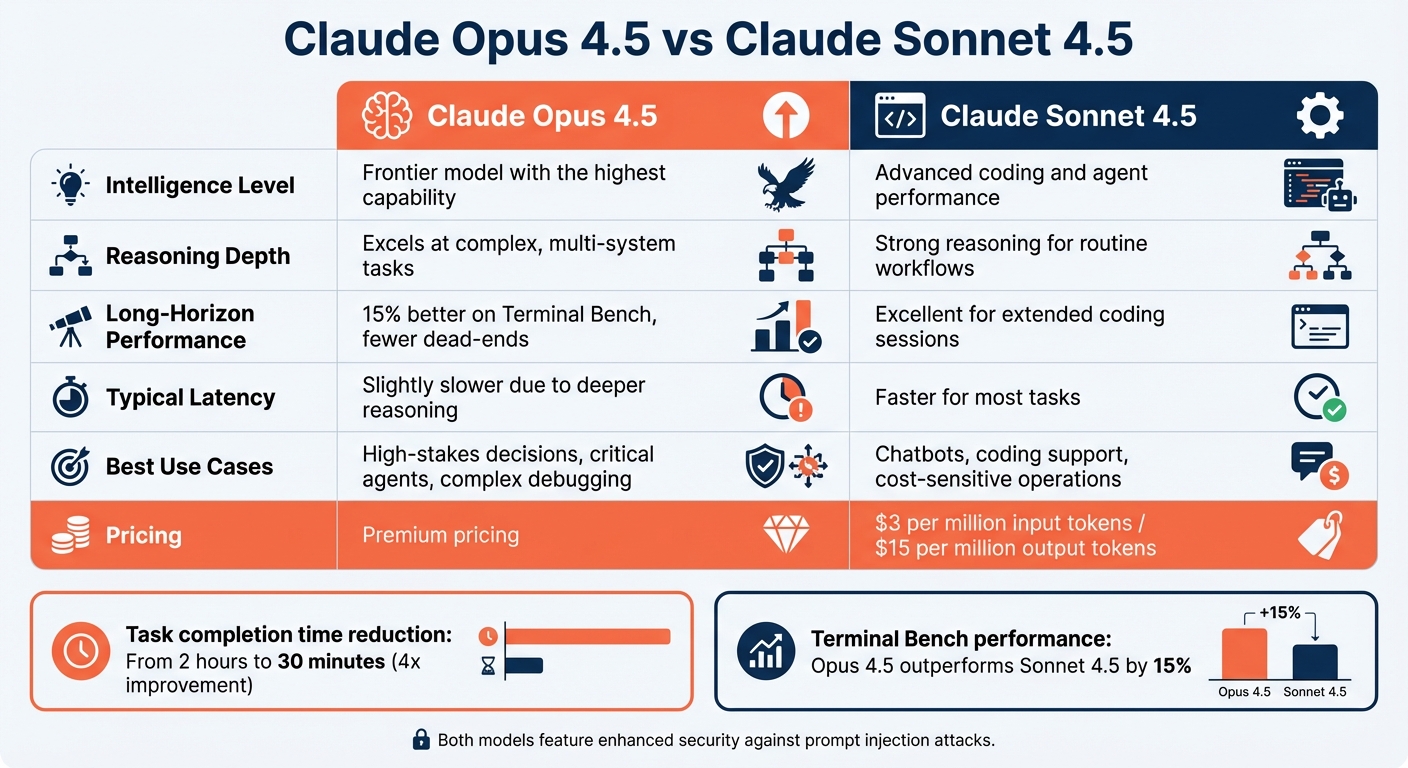
Claude Opus 4.5 vs. Claude Sonnet 4.5
The table below highlights the main differences between the two models based on their performance and safety metrics. Deciding between Opus 4.5 and Sonnet 4.5 depends on your specific needs and budget. Sonnet 4.5 remains priced at $3 per million input tokens and $15 per million output tokens, making it a practical choice for many applications. Meanwhile, Opus 4.5, though more expensive, delivers unmatched capabilities for the most demanding tasks.
| Feature | Claude Opus 4.5 | Claude Sonnet 4.5 |
|---|---|---|
| Intelligence Level | Frontier model with the highest capability | Advanced coding and agent performance |
| Reasoning Depth | Excels at complex, multi-system tasks | Strong reasoning for routine workflows |
| Long-Horizon Performance | 15% better on Terminal Bench, fewer dead-ends | Excellent for extended coding sessions |
| Typical Latency | Slightly slower due to deeper reasoning | Faster for most tasks |
| Best Use Cases | High-stakes decisions, critical agents, complex debugging | Chatbots, coding support, cost-sensitive operations |
| Pricing | Premium pricing | $3 / $15 per million input/output tokens (USD) |
Many U.S.-based organizations rely on Sonnet 4.5 for day-to-day tasks like chatbots, coding assistance, and internal tools. Opus 4.5, on the other hand, is often reserved for more demanding applications where its advanced planning and efficiency justify the additional cost.
Summary
Main Updates
Claude 4.5 introduces Opus 4.5 for advanced autonomous reasoning and Sonnet 4.5 for improved coding and agent-building capabilities. Opus 4.5 significantly enhances the efficiency of autonomous AI agents, reducing task completion times from 2 hours to just 30 minutes. At the same time, Sonnet 4.5 offers better performance without increasing costs.
Both models now feature stronger safeguards against prompt injection and related adversarial attacks. Sonnet 4.5, in particular, shows improved alignment, minimizing behaviors such as sycophancy, deception, and power-seeking. Developers also gain access to upgraded tools that simplify multi-step coding and agent workflows, making these models more practical and user-friendly.
What This Means for Users
These updates bring tangible advantages to both developers and enterprises. For software developers, Sonnet 4.5 serves as a seamless upgrade from Sonnet 4, offering enhanced support for complex, large-scale coding tasks. The addition of new SDKs and memory tools allows teams to design and manage coordinated, multi-agent systems more effectively.
For enterprise users, Opus 4.5 enables the automation of workflows that previously required human intervention. Tasks like litigation analysis, cybersecurity vulnerability patching, and in-depth data analysis are now handled with improved precision and speed. Companies using Snowflake Intelligence benefit from deeper, actionable insights, while businesses across various industries report noticeable efficiency gains on complex operations.
In high-security environments, both models stand out with their enhanced defenses against adversarial attacks. This makes them ideal for use in critical fields such as finance, legal, and cybersecurity. With improved alignment and robust protection, Claude 4.5 is better equipped to manage high-stakes decisions reliably compared to earlier versions.
FAQs
What are the key differences between Claude Opus 4.5 and Claude Sonnet 4.5?
Currently, there’s no detailed comparison available between Claude Opus 4.5 and Claude Sonnet 4.5. For specifics about their features or updates, it’s best to check the official release notes or documentation provided by Anthropic.
What is context compaction, and how does it enhance task management in Claude 4.5?
Claude 4.5 introduces context compaction, a refinement in how the AI processes and prioritizes information during extended conversations or tasks. By effectively summarizing and zeroing in on the most relevant details, Claude can maintain focus and manage complexity without losing critical context.
This improvement translates to smoother navigation through long discussions, more precise responses, and an overall streamlined experience when dealing with multi-step tasks or detailed workflows.
What new security measures are in Claude 4.5 to protect against adversarial attacks?
Unfortunately, there isn’t any detailed information available about the security measures in Claude 4.5 specifically designed to counter adversarial attacks. For more precise insights, it’s best to review the official release notes or documentation.