
Claude 4.5 Opus, released in November 2025, focuses on delivering faster and cost-efficient AI performance. As the latest evolution of the Claude 3 AI model architecture, it introduces several architectural breakthroughs. Here’s what stands out:
- Speed Gains: Cuts task completion time with fewer tokens (up to 76% less) and 67% lower costs compared to previous models.
- Effort Parameter: Users can choose between Low, Medium, and High effort levels to balance speed, detail, and cost.
- Advanced Features: Includes hybrid reasoning, programmatic tool calling, and improved context management, reducing delays and boosting efficiency.
- Performance Metrics: Scores 80.9% on SWE-bench Verified, surpassing competitors like Gemini 3 Pro and GPT-5.1.
- Real-World Impact: Handles tasks like coding, research, and automation faster, with fewer errors and smoother workflows.
For developers, researchers, and enterprises, Claude 4.5 Opus delivers faster responses, reduced costs, and improved accuracy across a range of tasks.
Technical Changes Behind Claude 4.5 Opus
Claude 4.5 Opus introduces several upgrades that significantly enhance its processing speed and task efficiency. These changes mark a shift in how the model handles resources and tackles complex operations.
One standout improvement is the hybrid reasoning architecture. Unlike earlier versions that worked with a fixed reasoning intensity, Claude 4.5 Opus can now switch between quick responses and more detailed, in-depth reasoning depending on the task at hand. This adaptability forms the basis for many of the other advancements.
Another major upgrade is programmatic tool calling. Instead of relying on multiple back-and-forth interactions with external tools, the model can now write and execute code directly within a controlled container. This streamlined process removes delays caused by repeated communication.
To tackle the issue of context overload, the Tool Search Tool brings a smarter approach. Instead of preloading hundreds of tool definitions into the context window – consuming up to 20,000 tokens – the model now searches for and loads only the tools needed for a specific task. This keeps the context window largely empty until it’s necessary, speeding up responses.
Additionally, context editing and compaction ensures smooth performance during long sessions. By clearing out old data such as unused thinking blocks and tool logs while keeping key insights intact, the model avoids the slowdown that often forced users to restart conversations in previous versions.
The Effort Parameter and Token Efficiency
Claude 4.5 Opus also introduces an effort parameter, giving users control over how much reasoning the model applies to a task. With three settings – Low, Medium, and High – users can balance speed and thoroughness based on their needs.
- Low effort: Ideal for tasks requiring quick, straightforward answers. This mode minimizes token usage and focuses on speed, making it perfect for automation tasks where responses are processed by systems rather than humans.
- Medium effort: A balanced option for most scenarios. Here, the model provides concise explanations and context, using 76% fewer tokens than Sonnet 4.5 while maintaining high coding performance (compared to token limits in other models). This setting is efficient for production environments, reducing costs and time.
- High effort: The default setting, designed for maximum detail. It includes thorough step-by-step reasoning and rich formatting. Even at this level, Claude 4.5 Opus uses 48% fewer tokens than its predecessor while delivering superior results. This mode is ideal for complex research or architectural reasoning tasks.
Across all settings, the model achieves a 19% reduction in token usage compared to earlier versions, ensuring cost-effective performance.
Search and Planning Optimization
Claude 4.5 Opus further refines its search and planning capabilities, enhancing both speed and accuracy. One of the key features is Plan Mode in Claude Code, which changes the way the model approaches coding tasks. Instead of jumping straight into execution, the model first generates a plan.md file outlining the solution and raising clarifying questions. This upfront planning reduces errors and eliminates the need for time-consuming retries.
Internal testing shows a 50% to 75% drop in tool-calling and build/lint errors. Fewer errors mean fewer iterations, which translates to faster task completion – an advantage for developers handling code migration or refactoring projects.
Another noteworthy feature is interleaved thinking, which allows the model to adjust its plans dynamically during multi-step tasks. By revising its strategy based on intermediate results, Claude 4.5 Opus avoids unnecessary processing and saves both time and tokens.
The use of parallel test-time compute further boosts efficiency. This method runs multiple solution attempts simultaneously, selecting the best outcome. Its effectiveness was demonstrated when Claude 4.5 Opus outperformed all human candidates in a 2-hour performance engineering exam – Anthropic‘s best result to date. By exploring multiple paths at once, the model arrives at solutions faster and with greater confidence.
Lastly, thinking block preservation has been fine-tuned to support extended interactions. Claude 4.5 Opus can now maintain coherent reasoning across sessions lasting over 30 hours, a significant leap from the 7-hour limit in earlier versions.
These updates, from architectural redesigns to algorithmic improvements, collectively enhance Claude 4.5 Opus’s speed, reduce token usage, and lower operational costs, making it a more efficient tool for complex tasks.
Context, Memory, and Tool Use Performance
Claude 4.5 Opus introduces refined capabilities in context management and tool integration, designed to improve real-time performance and tackle common challenges like running out of context space during extended sessions or making redundant tool calls. These updates build on earlier optimizations, enabling faster and more efficient task completion.
Improved Context Management and Compaction
Claude 4.5 Opus supports up to 200K tokens for standard users and up to 1M tokens for enterprise users. To handle lengthy sessions without slowing down, the model uses context editing to automatically remove older tool calls and results as it approaches token limits. This ensures smooth performance over extended interactions.
The model also preserves "thinking blocks", which retain essential reasoning history across multi-turn conversations. Instead of reprocessing an entire session, it keeps critical insights while discarding outdated data. Additionally, real-time token tracking helps maintain context awareness throughout use. In research scenarios, these combined memory and context features improved performance by nearly 15 percentage points.
These advancements in context management also set the stage for more efficient tool usage.
Enhanced Tool Use for Faster Problem Solving
Tool integration has been overhauled to streamline performance. Programmatic tool calling now allows multiple tools to run within a single container, reducing delays and token usage. On-demand tool loading ensures that the context window remains mostly empty – up to 95% – until a tool is actively required, saving between 10,000 and 20,000 tokens while maintaining high accuracy.
The results speak for themselves. Claude 4.5 Opus achieved a 50% to 75% reduction in tool calling errors and build/lint errors compared to earlier versions. On benchmarks like SWE-bench Verified (focused on software engineering tasks), it scored 80.9%, and on τ²-Bench (measuring multi-step agent behavior across tools), it reached 88.9%.
"We’re seeing 50% to 75% reductions in both tool calling errors and build/lint errors with Claude Opus 4.5. It consistently finishes complex tasks in fewer iterations with more reliable execution." – Anthropic Customer
One real-world example highlights its effectiveness. In November 2025, developer Simon Willison used Claude 4.5 Opus within the Claude Code interface to refactor the sqlite‑utils library. Over two days, the model handled most of the work, spanning 20 commits and 39 files, resulting in 2,022 additions and 1,173 deletions. It even implemented complex features like iterator‑based bulk inserts.
Benchmarks and Performance Data
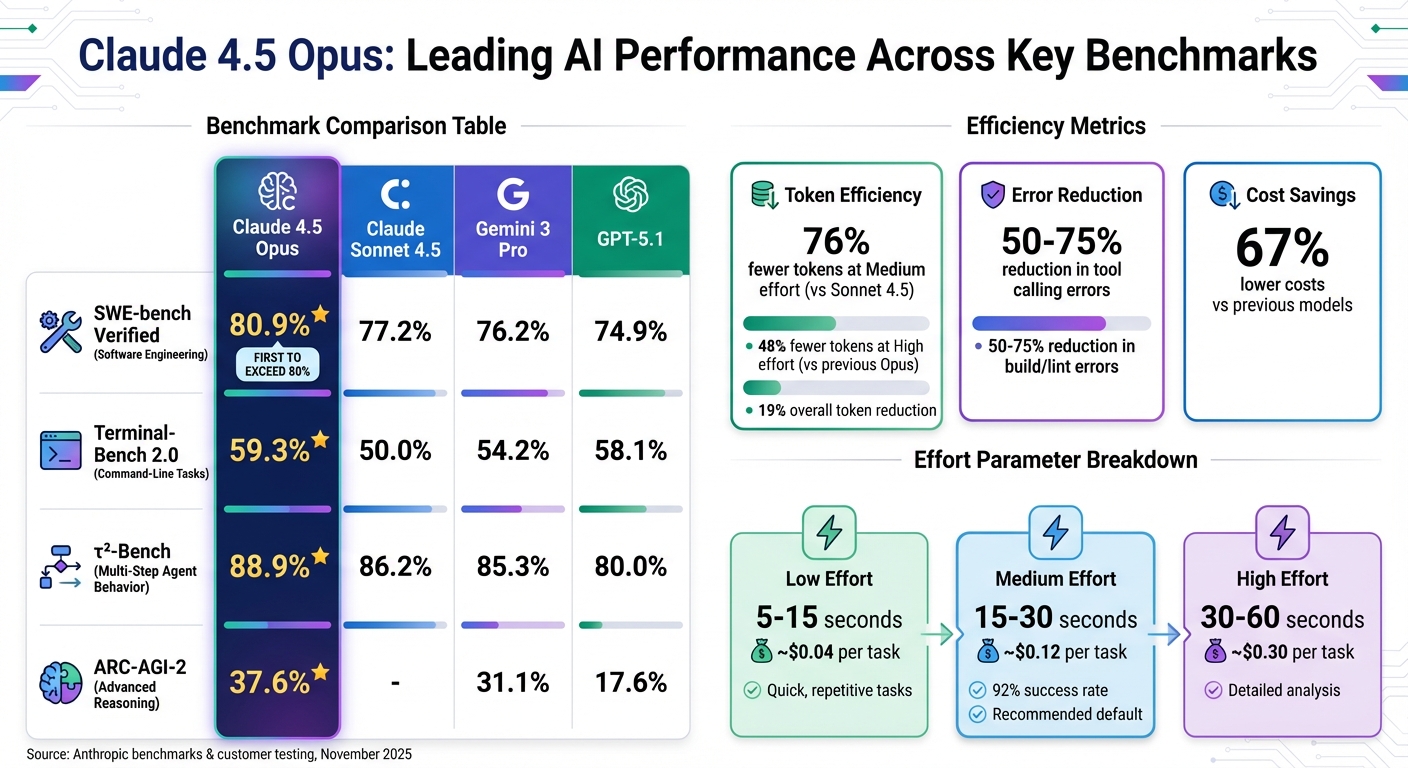
Claude 4.5 Opus Performance Benchmarks vs Competitors
Performance Metrics Across Models
Claude 4.5 Opus has set a new standard on SWE-bench Verified by scoring 80.9%, making it the first model to surpass the 80% mark on this benchmark designed for real-world software engineering tasks. It outpaces competitors like Sonnet 4.5 (77.2%), Gemini 3 Pro (76.2%), and GPT-5.1 (74.9%).
On Terminal-Bench 2.0, which evaluates command-line task execution, Opus 4.5 achieved a score of 59.3%, marking a 15% improvement over Sonnet 4.5’s 50.0%. It also outperformed Gemini 3 Pro (54.2%) and narrowly edged out GPT-5.1 (58.1%). For multi-step agent behavior, results from the τ²-Bench show Opus 4.5 leading with 88.9%, ahead of Sonnet 4.5 (86.2%), Gemini 3 Pro (85.3%), and GPT-5.1 (80.0%).
Efficiency gains are another area where Opus 4.5 stands out. At medium effort, it matches Sonnet 4.5’s top SWE-bench score while using 76% fewer tokens. At high effort, it exceeds Sonnet 4.5’s performance by 4.3 percentage points, consuming 48% fewer tokens. Developers also report using up to 65% fewer tokens for long-term coding tasks compared to earlier models.
| Benchmark | Claude 4.5 Opus | Claude Sonnet 4.5 | Gemini 3 Pro | GPT-5.1 |
|---|---|---|---|---|
| SWE-bench Verified | 80.9% | 77.2% | 76.2% | 74.9% |
| Terminal-Bench 2.0 | 59.3% | 50.0% | 54.2% | 58.1% |
| τ²-Bench (Agents) | 88.9% | 86.2% | 85.3% | 80.0% |
| ARC-AGI-2 | 37.6% | N/A | 31.1% | 17.6% |
These results highlight how improved performance metrics translate into faster and more efficient workflows.
Faster Workflows in Practice
The benefits of these benchmarks are not just theoretical – they translate directly into practical time and cost savings. For example, the GitHub Copilot team observed that Opus 4.5 "surpasses internal coding benchmarks while reducing token usage by 50%, particularly excelling in tasks like code migration and code refactoring".
"Opus 4.5 beats Sonnet 4.5 and competition on our internal benchmarks, using fewer tokens to solve the same problems. At scale, that efficiency compounds."
- Michele Catasta, President at Replit
In financial modeling workflows, internal evaluations revealed a 20% improvement in accuracy and a 15% boost in efficiency. Additionally, self-improving AI agents achieved peak performance in just four iterations with Opus 4.5, compared to over ten iterations required by other models to reach similar results.
sbb-itb-f73ecc6
Optimizing Claude 4.5 Opus for Speed
Adjusting the Effort Parameter for Different Tasks
Claude 4.5 Opus introduces an effort parameter that determines how thoroughly the model tackles a task. This beta feature offers three levels: Low, Medium, and High, giving you control over the balance between speed, token usage, and the depth of responses.
Here’s how the effort levels break down:
- High effort: Takes around 30–60 seconds, costing approximately $0.30 per task. Ideal for tasks requiring detailed plans or in-depth analysis.
- Medium effort: Completes tasks in 15–30 seconds at about $0.12 per task, with a 92% success rate. A good default for most use cases.
- Low effort: Finishes tasks in 5–15 seconds, costing roughly $0.04 per task. Best suited for simple, repetitive tasks or high-volume automation.
To enable this feature, include the effort-2025-11-24 beta header in your API requests and set the desired level in the output_config object. The effort parameter influences all tokens in a response, including text explanations and tool calls. Lower effort levels result in more concise outputs and fewer tool calls, while higher levels provide more comprehensive responses and detailed reasoning.
For most production tasks, Medium effort is the recommended starting point. Use High effort for tasks that demand precision, such as security reviews or complex problem-solving. Reserve Low effort for straightforward tasks handled by sub-agents or for scenarios requiring speed and scalability. When paired with Tool Search, the effort parameter significantly enhances efficiency.
Next, we’ll explore how Fello AI simplifies multi-model comparisons, further improving speed and performance.
Using Fello AI for Model Comparison
Building on the efficiency of the effort parameter, Fello AI offers a seamless way to compare model performance in real time. With no need for multiple subscriptions, you can access leading models – including Claude 4.5 Opus, GPT-5.2, and Gemini 3 – through a single platform on Mac, iPhone, and iPad.
Fello AI supports a multi-model workflow, letting you switch between models based on the task. For example, you might rely on Gemini 3 Pro for research, given its top performance in blind A/B testing for chat, and then pivot to Claude 4.5 Opus for complex coding tasks requiring multi-file consistency. The platform allows you to upload the same file to different models, making it easy to identify which one delivers the fastest and most accurate results for your needs.
No single model excels at everything. Claude 4.5 Opus leads in web development and autonomous coding, boasting an 80.9% SWE-bench Verified score. Meanwhile, Gemini 3 Pro outshines in chat performance, and GPT-5.2 stands out for rapid prototyping. By testing models side by side in Fello AI, you can fine-tune your approach, selecting the best model and effort level for speed and cost efficiency. This approach aligns with the scalability and performance strategies discussed throughout this guide.
Conclusion: Claude 4.5 Opus Performance Summary
Speed Improvements Overview
Claude 4.5 Opus brings a noticeable boost in speed thanks to its refined architecture and the introduction of selectable effort levels. These effort settings – High, Medium, and Low – allow users to balance thoroughness with token efficiency. At the Medium effort level, the model matches Sonnet 4.5’s best coding performance while using 76% fewer output tokens. At High effort, it surpasses Sonnet 4.5 by 4.3 percentage points on SWE-bench, all while consuming 48% fewer tokens compared to earlier Opus versions.
The model also reduces delays through programmatic tool calling and on-demand loading of tool definitions via Tool Search. Context compaction eliminates outdated information, ensuring smooth performance during extended sessions. Together, these features contribute to a 67% cost reduction compared to previous iterations.
On SWE-bench Verified, Claude 4.5 Opus achieved an impressive 80.9%, becoming the first model to exceed the 80% mark for real-world software engineering tasks. Early testers have noted significant improvements, with tool-calling and build errors dropping by 50% to 75%. Even complex tasks, like 3D visualizations that once took two hours, now only take thirty minutes.
These advancements directly translate into faster workflows and greater efficiency for developers and researchers alike.
How Speed Improvements Help Users
For developers, Claude 4.5 Opus provides faster iterations and reduced costs through its efficient token usage and built-in tool-calling capabilities. Tasks that rely on maintaining consistency across multiple files or require long-term planning – such as codebase refactoring or debugging intricate systems – are now completed more quickly and with greater precision. The model’s perfect 100% score on the AIME 2025 math benchmark using Python tools further highlights its ability to tackle technical challenges under tight time constraints.
Writers and researchers also benefit from the model’s flexible effort parameter, which allows them to balance speed and depth depending on the task. When combined with enhanced memory and sub-agent structures, Opus 4.5 has demonstrated a 15 percentage point improvement in deep-research evaluations.
For enterprise teams juggling complex toolkits across platforms like Jira, GitHub, and Slack, the model’s streamlined context windows cut costs while maintaining high performance. Additionally, its low 4.7% attack success rate for prompt injections – significantly better than Gemini 3 Pro’s 12.5% and GPT-5.1’s 21.9% – makes it a safer choice for automation tasks. Whether comparing models through Fello AI or deploying agents in production, the speed improvements in Opus 4.5 lead to smoother workflows and reduced costs across writing, coding, research, and planning tasks. These enhancements make it a reliable tool for professionals seeking efficiency and precision.
FAQs
What is the effort parameter, and how does it affect Claude 4.5 Opus’s performance?
The effort parameter in Claude 4.5 Opus lets you control the trade-off between speed and the depth of responses. Opting for a lower effort setting means quicker, more cost-effective answers, though they may lack detailed reasoning. On the other hand, a higher effort setting takes longer but provides more thorough insights and well-rounded responses.
This feature allows you to customize the model’s performance based on your priorities – whether you need rapid results or a more comprehensive output for tasks like writing, brainstorming, or conducting research.
What makes Claude 4.5 Opus faster and more efficient?
Claude 4.5 Opus delivers faster performance thanks to several smart upgrades. It leverages prompt caching to cut down processing time, streaming message delivery for quicker responses, and batch processing to manage multiple requests more effectively. On top of that, a new context compaction layer trims token usage and reduces memory demands, boosting efficiency by about 80% compared to the earlier Opus model.
These enhancements make Claude 4.5 Opus a strong choice for real-time applications, ensuring a smoother and more responsive experience across a range of tasks.
What makes Claude 4.5 Opus better at managing long conversations?
Claude 4.5 Opus stands out for its ability to manage lengthy conversations, thanks to its 200,000-token context window and sophisticated context-compaction system. This system smartly condenses earlier parts of the discussion, allowing the model to stay efficient and keep track of the conversation without losing focus, even during extended interactions.
With these features, Claude 4.5 Opus ensures smooth continuity and relevance, making it a perfect fit for tasks that demand prolonged, detailed discussions or complex workflows.