
The Claude API enables developers to build advanced media applications using Anthropic’s language models, such as Claude 4 and 3.5. Key features include a 200,000-token context window, which processes large datasets like movie scripts or user histories, and custom API endpoints for real-time integration with external services like IMDb or Spotify. These tools help media platforms deliver personalized recommendations, dynamic playlists, and sentiment-based TV show suggestions.
Key Takeaways:
- 200,000-token context: Ideal for large-scale inputs like full scripts or extensive user data.
- Custom Endpoints via MCP: Enables real-time queries to external APIs for tailored recommendations.
- Batch Processing: Reduces costs by up to 50% for high-volume tasks.
- Model Options: Choose based on task complexity and budget, e.g., Claude 4.5 Sonnet for in-depth reasoning or Claude 3 Haiku for simpler tasks.
The API supports integration with platforms like Amazon Bedrock or Google Vertex AI and tools like Fello AI for prototyping. Developers can optimize costs and performance using prompt caching, streaming responses, and monitoring token usage. These features make Claude API a powerful tool for creating user-centric media solutions.
Use MCP to Integrate Your API with Claude – Full Step-by-Step Guide
Prerequisites for Claude API Integration
To get started with Claude API, you’ll need to set up an Anthropic Console account and generate an API key for authentication. Using an official SDK – available for languages like Python, TypeScript, Java, Go, C#, Ruby, or PHP – is highly recommended. These SDKs simplify tasks like managing authentication, handling retries, and enabling streaming.
Make sure you’re familiar with RESTful APIs and JSON formatting, as these are essential for interacting with the Messages API endpoint (POST /v1/messages). If you’re working with large datasets or media-heavy applications, understanding how to manage Claude’s impressive 200,000-token context window will be crucial. Additionally, the Anthropic Workbench is a great tool to refine your prompts before diving into coding.
Once you’ve covered the basics, take some time to explore how Claude 4.5’s features can enhance media recommendation systems.
Claude API Features Overview
Claude 4.5 stands out thanks to its Constitutional AI training, which allows it to self-correct and generate safer, more ethical content – an essential feature when creating recommendations for diverse audiences. Its hybrid reasoning capabilities make it highly effective for tasks like analyzing sentiment in TV reviews.
For visual media, the Vision API is a game-changer. It can extract insights from images such as movie posters, charts, or infographics. If you’re managing large-scale operations, the Message Batches API offers asynchronous processing at a 50% cost reduction compared to standard calls. This is especially useful for generating weekly personalized content summaries for large user bases without the need for real-time responses.
Tools and Platforms Selection
Claude can be deployed on major cloud platforms like Amazon Bedrock, Vertex AI, or Azure AI, which offer integrated billing and compliance options. These platforms are ideal for teams already working within established cloud ecosystems or those with specific regulatory requirements.
For the fastest access to Claude’s latest features, using the Claude API directly through Anthropic’s platform is your best bet. Standard API endpoints support requests up to 32 MB, while the Batch API can handle up to 256 MB, and the Files API goes even further at 500 MB. If your recommendation system needs to process specific data formats – like movie IDs or genre tags – enabling strict: true in your tool definitions ensures schema compliance.
| Feature | Direct Claude API | Third-Party (Bedrock/Vertex/Azure) |
|---|---|---|
| Access | Direct access to latest models first | Integrated with cloud provider ecosystem |
| Billing | Anthropic direct billing | Consolidated cloud provider billing |
| Best For | New integrations and full feature access | Existing cloud commitments and regulated industries |
Accessing Claude via Fello AI
For quick prototyping, Fello AI offers an intuitive way to interact with Claude. Available as a native app for macOS, iPhone, and iPad, Fello AI provides direct access to Claude 4.5, alongside other models like GPT-5.1, Gemini, Grok, and DeepSeek. This setup is perfect for running the same prompt – such as "Generate a 10-song playlist based on this mood" – across multiple models to compare outputs before committing to a specific API provider.
Fello AI also includes features like a prompt library, full-text chat search, and prompt pinning, which make testing and prototyping faster and easier. Best of all, you can start testing immediately after downloading it from the Mac App Store – no need to configure an API key upfront.
"For macOS users, Fello AI offers one of the best desktop experiences available for interacting with Claude." – Fello AI
Designing Custom API Endpoints for Media Recommendations
Claude API Model Comparison: Pricing and Use Cases for Media Applications
Once your Claude API access is ready, the next step is creating endpoints tailored to specific media recommendation tasks. These could include suggesting movies based on viewing history, crafting playlists to match a user’s mood, or recommending TV shows using sentiment analysis. Each endpoint should address a distinct media use case.
The backbone of any custom endpoint lies in the Messages API (POST /v1/messages). Since Claude’s API is stateless, you’ll need a backend session manager to track user preferences and append them to the messages array before sending requests to Anthropic’s servers. This backend setup not only maintains context – like remembering a user’s love for sci-fi but dislike for slow-paced dramas – but also secures your API key and handles CORS restrictions.
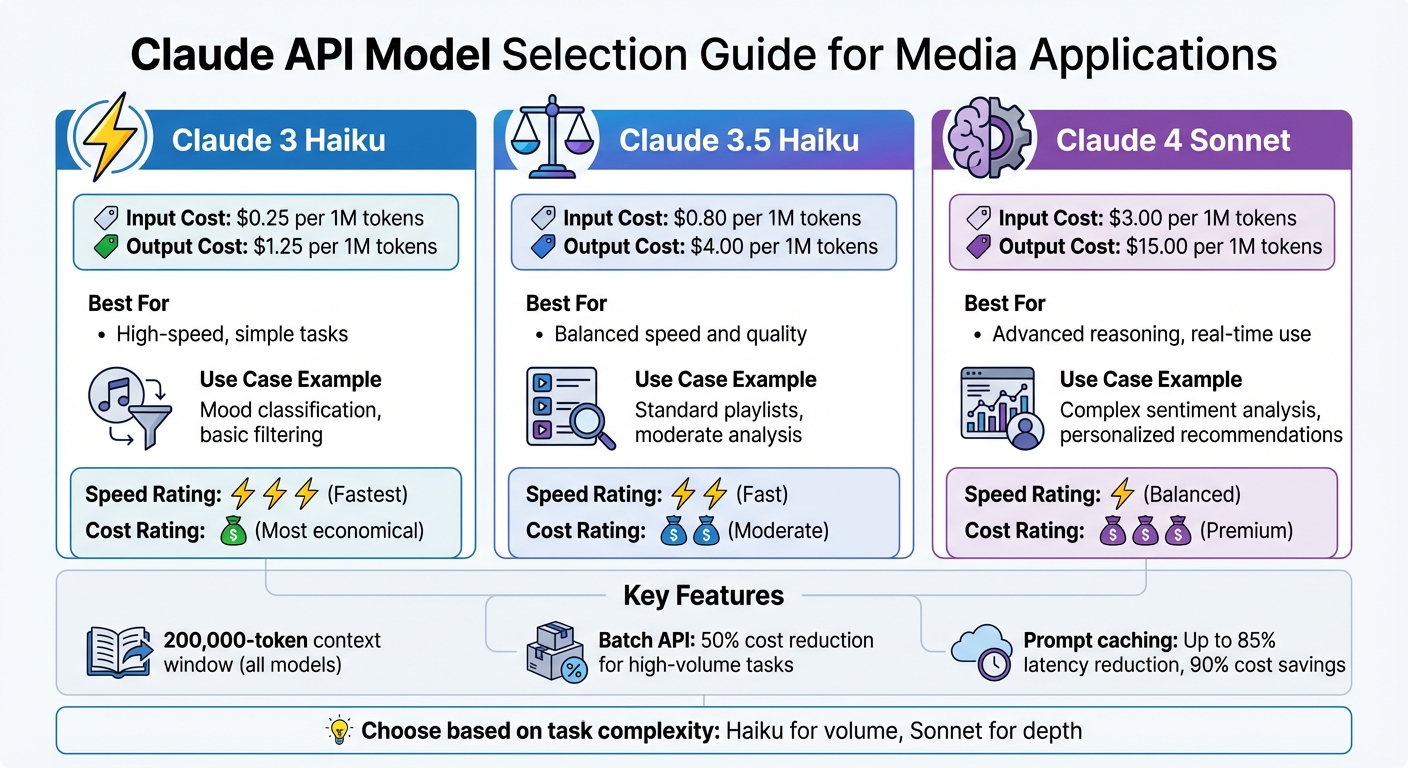
Choosing the right model is key to balancing performance and cost. Prices range from $0.25 per million input tokens for Claude 3 Haiku to $3 per million input tokens for Claude 4.5 Sonnet, with output costs scaling accordingly. For real-time, detailed recommendations, Claude 4.5 Sonnet offers both speed and depth. On the other hand, if your use case involves handling a high volume of simpler requests, like mood classification, Claude 3 Haiku is a cost-efficient choice. For workflows that require deeper analysis, Claude 4.5 Opus provides the necessary reasoning capabilities.
To pull data from external sources like movie databases or streaming APIs, you can use the MCP integration mentioned earlier. For instance, a query_database function can fetch movie ratings or availability, while tools like Zod ensure the data passed to your APIs is properly formatted. To improve responsiveness, enable streaming by setting stream: true in your API request, allowing recommendations to appear token-by-token. Additionally, the Token Counting API (POST /v1/messages/count_tokens) helps monitor user history size, ensuring cost efficiency. These strategies expand on earlier approaches, tailoring your endpoints to tackle specific media challenges.
Endpoint for Personalized Movie Suggestions
A movie recommendation endpoint can leverage Claude’s massive 200,000-token context window to process extensive user data, including watch histories, detailed reviews, and preference profiles. This gives the model a "deep memory" of user viewing patterns.
Start by crafting a system prompt that defines Claude’s role as a movie recommendation assistant. Anthropic’s guidelines suggest avoiding unnecessary flattery in responses:
"Claude never starts its response by saying a question or idea or observation was good, great, fascinating, or any other positive adjective."
To enhance the quality of recommendations, use structured prompts with clear instructions. Research shows that structured formatting can boost viewer retention rates from around 42% to 68%.
Endpoint for Dynamic Music Playlist Generation
Music recommendation endpoints follow similar principles but require adjustments for speed and creativity. Combining prompt caching with embeddings that capture mood and genre is an effective approach. Cache commonly used prompts or user data for up to an hour to reduce latency.
Define a system prompt that positions Claude as an expert music curator. Use concise instructions to streamline the process, such as:
"Generate 10-song JSON playlist: [Mood], [Genre]"
Streaming responses can further enhance the user experience by delivering playlist items in real time, one by one.
Here’s a quick reference table for model options:
| Model | Input Cost (per 1M tokens) | Output Cost (per 1M tokens) | Best For |
|---|---|---|---|
| Claude 3 Haiku | $0.25 | $1.25 | High-speed, simple tasks |
| Claude 3.5 Haiku | $0.80 | $4.00 | Balanced speed and quality |
| Claude 4 Sonnet | $3.00 | $15.00 | Advanced reasoning, real-time use |
For more complex tasks, like generating multiple playlists for various moods simultaneously, consider using parallel API calls with tools like AsyncAnthropic. Connecting Claude to external music databases via an MCP Connector can help fetch real-time data effortlessly. Testing prompts in the Anthropic Workbench and experimenting with temperature settings can fine-tune the creativity and randomness of music suggestions.
Endpoint for TV Show Recommendations via Sentiment Analysis
Sentiment analysis offers a unique way to recommend TV shows by aligning user emotions with specific content themes. Claude excels at classification tasks, making it possible to analyze thousands of reviews or user inputs to identify emotional states. Build your endpoint using the Messages API, and define Claude’s role as a "Sentiment-Aware Media Expert" to ensure recommendations align with the user’s mood. Adjust the temperature parameter to balance consistency with variety.
Claude 4.5 incorporates Constitutional AI principles, ensuring sentiment-based recommendations avoid harmful content and stay ethically sound. As Fello AI notes:
"Claude 4.5 is optimized for both low latency and deep reasoning… enabling large-scale analysis."
This capability is especially valuable for processing nuanced emotions, allowing the model to distinguish between feelings like "sad but hopeful" and "deeply depressed." When a sentiment like "melancholy" is detected, Claude can automatically trigger a function (e.g., query_shows) to fetch dramas that explore themes of personal growth. As Miguel Rebelo from Zapier explains:
"If you need to… get a sentiment analysis of thousands of online reviews, Claude can help."
For enterprise-level scenarios with high volumes of sentiment analysis requests, the Batch API offers up to a 50% cost reduction through asynchronous processing. Deploying the API via services like Amazon Bedrock or Google Vertex AI can streamline billing and ensure high availability. With its 200,000-token context window, Claude can analyze extensive viewing histories alongside current sentiment data. Multi-turn conversations further refine recommendations based on real-time feedback.
sbb-itb-f73ecc6
Testing and Optimizing Custom Endpoints
Once you’ve designed your custom endpoints, the next step is to ensure they perform well and stay cost-efficient through rigorous testing and fine-tuning. Incorporate a mix of unit, integration, contract, and end-to-end tests that reflect how users will interact with your application. For media recommendation systems, it’s crucial to simulate high-traffic scenarios to test how your endpoints handle peak loads.
You can use tools like Claude to generate test cases directly from your API documentation or Swagger specs. When evaluating recommendation quality, there are two main approaches: code-based grading for straightforward checks (like verifying if a movie recommendation matches a requested genre) and LLM-based grading for more nuanced assessments. For LLM-based grading, provide clear evaluation criteria and encourage the model to "think first" before assigning scores. Anthropic’s documentation emphasizes:
"More questions with slightly lower signal automated grading is better than fewer questions with high-quality human hand-graded evals."
Performance monitoring is another critical element for ensuring user satisfaction. Keep an eye on key metrics like Time to First Token (TTFT) and 95th percentile response times to maintain a seamless user experience. For media applications, aim for latencies under 300 milliseconds for real-time interactions, though under one second is generally acceptable. Tools like k6, Apache JMeter, or Postman can help simulate high-usage scenarios. Additionally, monitor your cache hit rate using CloudWatch, aiming for rates above 70% to maximize efficiency.
Cost management is just as important. Poorly optimized development can lead to skyrocketing expenses. Track token usage across inputs, outputs, and cache operations to pinpoint inefficiencies. Set up alerts for "retry storms", where misconfigured SDKs repeatedly retry failed requests, leading to significant cost spikes. To control costs further, enforce quotas by storing usage limits in a database like DynamoDB and using Lambda functions to aggregate token consumption every 15 minutes.
Comparing Hosting Options for Scalability
Your choice of hosting platform can significantly influence both performance and cost. Amazon Bedrock provides cross-region inference through Global Profiles, which doubles throughput quotas and ensures automatic failover during traffic surges. It also offers Provisioned Throughput, which can save up to 60% on costs for predictable, high-volume workloads. On the other hand, Google Vertex AI features global endpoints with dynamic routing for maximum uptime but charges a 10% premium for Regional endpoints when data residency is required.
| Hosting Platform | Managed Infrastructure | Cost Efficiency | Media-Specific Tools |
|---|---|---|---|
| Vertex AI | Yes | Moderate | Supports image and text generation |
| Amazon Bedrock | Yes | High | Extensive integrations with AWS services |
With these hosting options in mind, the next step is to focus on strategies to enhance endpoint responsiveness and reliability.
Improving Endpoint Performance
One effective way to reduce latency and lower costs is through prompt caching, which can decrease latency by up to 85% and cut costs by as much as 90% for repeated contexts. For prompts exceeding 500 tokens, implement caching. For instance, if your movie recommendation service relies on a large catalog of film descriptions, use a cache control directive like cache_control={"type": "ephemeral"} to avoid reprocessing the same data with every request.
Model selection plays a significant role in balancing speed and cost. For example, Claude Haiku 4.5 is twice as fast as Sonnet 4 and five times cheaper for simpler tasks like mood classification. For more complex reasoning tasks, reserve models like Claude Sonnet 4.5. Additionally, enable streaming by setting stream: true to send recommendations incrementally, which improves the perceived speed for users.
To ensure your optimizations maintain quality, monitor user success metrics such as "Tool Acceptance Rates" – the ratio of accepted to rejected suggestions – to gauge the relevance of your recommendations. Use OpenTelemetry to gather detailed metrics that standard cloud logging might miss, such as which types of recommendations users engage with the most. High-performing systems have achieved cache efficiency ratios as high as 39:1, with 78,000 cache reads compared to just 2,000 cache writes.
Conclusion and Key Takeaways
Custom endpoints offer a powerful way to handle large media libraries while ensuring recommendations stay aligned with your brand’s identity. Thanks to Claude’s extensive context window, it’s possible to process entire movie catalogs or user watch histories in a single request. Plus, its Constitutional AI framework ensures that recommendations adhere to brand guidelines. For instance, one content creator saw video completion rates jump from roughly 42% to 68% by using AI-generated structured frameworks.
To take these capabilities further, combining MCP and batching techniques can significantly boost performance. MCP servers support real-time queries to live media databases, keeping availability up-to-date. Meanwhile, the Message Batches API helps cut costs by 50% when handling high-volume processing tasks. Selecting the right model for specific tasks is equally important – Claude Haiku 4.5 excels in speed, while Sonnet 4.5 balances reasoning and efficiency, as covered earlier.
Developers can also take advantage of tools like Fello AI to quickly prototype solutions. Fello AI provides instant access to Claude 4.5, alongside other models like GPT-5.1 and Gemini. These tools make it easier to experiment and refine ideas into production-ready systems.
The real key to success is treating API optimization as an ongoing effort. Regularly monitor performance metrics and token usage to avoid unexpected cost spikes. Streaming mode can also be a game-changer for real-time interactions. Whether you’re building personalized movie recommendation engines or dynamic playlist generators, combining Claude’s expansive context window, real-time integration features, and cost-efficient batching ensures your system can grow with your audience while maintaining high-quality output.
FAQs
How does Claude’s 200,000-token context window enhance media applications?
Claude’s 200,000-token context window makes it possible for media applications to process entire scripts, articles, transcripts, or even vast document collections in just one API call. This feature allows the model to grasp the entirety of lengthy content, enabling it to generate more precise recommendations, detailed summaries, and contextually relevant outputs specifically designed for media-related tasks.
With the ability to manage large-scale content effortlessly, Claude helps media platforms create smarter, more tailored experiences for their audiences.
How can I save costs when using the Claude API for large-scale tasks?
To keep costs down when managing high-volume tasks with the Claude API, focus on choosing the right model, reducing token usage, and improving request efficiency.
- Pick the right model: For simpler tasks, opt for more affordable models like Haiku instead of higher-end options like Claude 4.5.
- Limit token usage: Use concise prompts, trim conversation history, and set a
max_tokenslimit to avoid unnecessary output. - Batch your requests: Combine multiple requests into one batch to take advantage of discounted token rates.
- Leverage cached responses: Design prompts to utilize Claude’s caching system, storing results for identical inputs to prevent redundant API calls.
By implementing these methods, you can manage costs effectively without compromising the performance required for media and entertainment applications.
How does Claude’s Constitutional AI ensure ethical and responsible media recommendations?
Claude’s Constitutional AI operates based on a predefined set of ethical guidelines, referred to as its "constitution." These rules are designed to ensure that its recommendations remain responsible and safe. The principles focus on steering clear of hate speech, misinformation, copyright infringement, bias, and harmful advice. Before providing any suggestions, the model reviews its responses to ensure they comply with these ethical standards.
This built-in self-check system reinforces trust and integrity, making it a dependable resource for applications in media and entertainment.